Das IDE schaut in die Glaskugel und fragt: Wie werden sich digitale Editionen in den nächsten 20 Jahren entwickeln? Auf der Suche nach Antworten veranstalten wir am 02.-04. September 2026 in Wuppertal eine Konferenz und laden herzlich zu Paper-Proposals ein. Details dazu auf https://editopia2026.i-d-e.de/.
Die Kerninfos:
Einreichungsfrist ist vom 22. März auf den 5 April 2026 verlängert worden. Die Benachrichtigung über die Annahme erfolgt bis Ende April 2026. Eine Publikation ausgewählter Beiträge ist in der SIDE-Schriftenreihe vorgesehen. Die Konferenzsprachen sind Englisch und Deutsch. Die Teilnahme ist auf 60 Personen begrenzt. Eine Tagungsgebühr wird nicht erhoben.
Format:Vorträge, 20 Minuten Länge
Abstract:2000-4000 Zeichen inkl. Leerzeichen und Referenzen
Wir freuen uns, Ihnen die 20. Ausgabe der Rezensionszeitschrift RIDE anzukündigen, die seit 2014 vom Institut für Dokumentologie und Editorik (IDE) herausgegeben wird.
Die aktuelle Ausgabe wird von Ulrike Henny-Krahmer und Martina Scholger herausgegeben und widmet sich digitalen wissenschaftlichen Editionen. Sie enthält fünf Rezensionen (drei auf Englisch, zwei auf Deutsch):
Sewing text and images together in the digital environment. A review of Bayeux Tapestry Digital Edition von Manuele Veggi: http://doi.org/10.18716/ride.a.20.3
RaDiHum20, der Digital Humanities Podcast, hat eine Folge zu RIDE, dem Review Journal for Digital Editions and Resources, veröffentlicht, die am 20. Dezember 2024 erschienen ist. Jonathan Geiger, Jascha Schmitz und Mareike Schumacher von RaDiHum20 haben mit Ulrike Henny-Krahmer, Frederike Neuber und Martina Scholger, den Managing Editors von RIDE, gesprochen.
Thematisiert wird alles rund um RIDE: Wie spricht man es richtig aus? Seit wann gibt es RIDE, wie ist die Zeitschrift entstanden? Was hat es mit Fragebögen und Rezensionskriterien auf sich? Welche Rolle spielen Daten in RIDE und wie könnten die Rezensionen der Zukunft aussehen? Dies und mehr gibt es hier im Podcast zu hören: https://radihum20.de/radihum20-spricht-mit-ride/.
In collaboration with the Institute of Documentology and Scholarly Editing, the Text+ consortium (https://text-plus.org/) of the German National Research Data Infrastructure (NFDI) invites again authors to submit reviews of digital scholarly editions for the journal RIDE (https://ride.i-d-e.de/). The reviews should be based on the IDE criteria for reviewing digital editions and focus on the application of the FAIR principles for this special issue.
Two RIDE volumes have already been published in 2023/24 in collaboration between IDE and Text+, and now a second round of reviews focusing on the implementation of the FAIR principles in digital editions is to follow. The editors of the issue are Christoph Kudella, Marie Millutat (both Niedersächsische Staats- und Universitätsbibliothek Göttingen) and Frederike Neuber (Berlin-Brandenburg Academy of Sciences and Humanities).
The following blog post was translated by Deepl and only slightly corrected. The original blog post was written in German and published on the DHd-Blog.
***
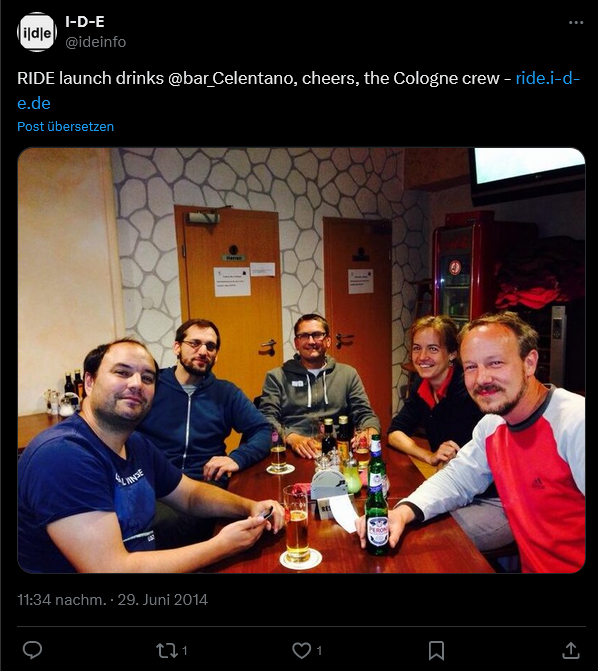
Exactly 10 years ago, on 20 June 2014, the first issue of the review journal RIDE – A Review Journal for Digital Editions and Resources by the Institute for Documentology and Scholarly Editing (IDE) was published. While we are celebrating the 10th birthday on Mastodon in the Fediverse from our IDE account under the hashtag #10YearsRIDE, the launch of the digital journal was advertised on Twitter with a rather simple post (see Fig. 1). Even back then, some people wondered how to pronounce RIDE: /ri:de/ (German) or /raɪd/ (English)? For the attentive readers, we will reveal the secret at the end of this post.
Fig. 1: The first tweet.
RIDE was launched by the IDE to create a forum for discussing digital editions, to contribute to quality assurance, to improve current practice and to drive future development.[1] Digital editions were and are[2] usually ignored by traditional review journals and thus hardly recognised in the Humanities disciplines. This in turn means that the creators of digital editions – from editors and data modellers to software developers – are often denied recognition of their achievements by the academic community. In order to counteract this, RIDE should create an interdisciplinary exchange forum in which digital research resources are reviewed in their entirety, i.e. both from a subject-specific and content-related perspective and, above all, from a methodological and technical perspective.
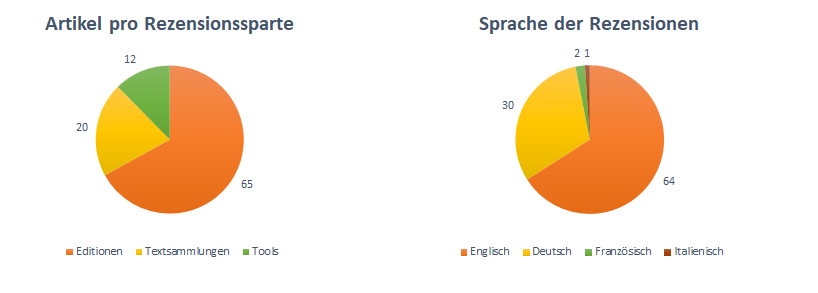
As of today (June 2024), a total of 97 digital resources have been reviewed in 18 issues in RIDE. The majority of the reviews, 65 in total, are dedicated to „Digital Scholarly Editions“. A further 20 reviews discuss „Text collections“ (since 2017) and so far 12 reviews have focussed on „Tools and working environments for digital editions“ (since 2022) (Fig. 2). In the „Editions“ section, there are now also thematic issues: two issues on editions of letters and two issues focussing on the implementation of the FAIR principles. Around two thirds of the reviews are currently available in English and one third in German, with two reviews in French and one in Italian (Fig. 3). For all three review categories – digital editions, text collections and tools – there are criteria catalogues[3] created by the IDE for reviewing the respective resources, which are intended to support the reviewers in their assessment and serve as a guide. Through various feedback from the community, we know that the criteria catalogues are now not only used for reviewing in RIDE, but also as best-practice guidelines when planning and developing new resources[4].
Fig. 2 / 3: Left: Articles per section (Editions, Text Collections and Tools); Right: Languages of the reviews (English, German, French, Italian).
Due to the increasing establishment of RIDE, the effort required to operate and further develop the journal has multiplied over the years. Initially led by one managing editor, it was then managed by a team of two, and in the meantime by a team of three people from the IDE circle.[5] While the editors of the issues were exclusively IDE members in the first few years, guest editors now also plan and publish entire issues.[6] The members of the IDE collaborate for certain editorial tasks (including proof reading) and technical tasks.
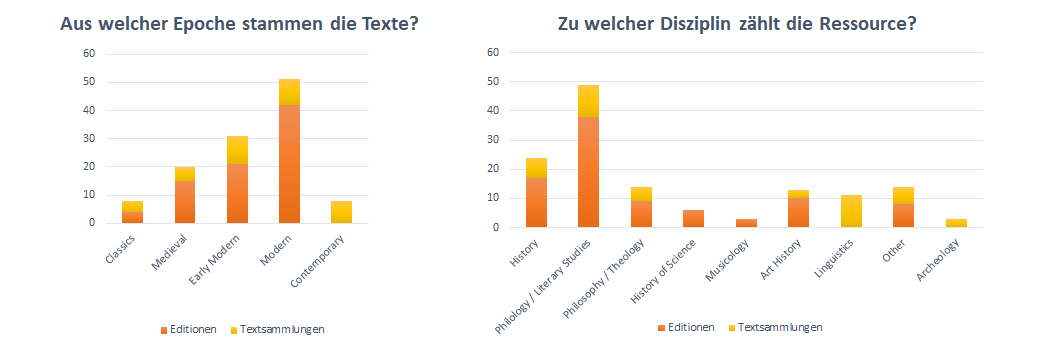
In RIDE, each review consists of the actual review text and a factsheet. The latter is a questionnaire with largely formalised answer options so that the reviewed resources can be more easily compared with each other.[7] At the same time, the data collected provides an overview of what has already been reviewed in RIDE, for example the epochs and disciplines from which the reviewed edition projects originate (Figs. 4 and 5). The range of subjects in RIDE covers almost all humanities (text-related) disciplines. However, it is also clear that, despite the interdisciplinary nature of the journal, the majority of the reviewed editions and text collections can be located in literary studies and in the modern period[8].
Fig. 4 / 5: Left: From which epoch are the texts? Right: To which discipline belongs the resource.
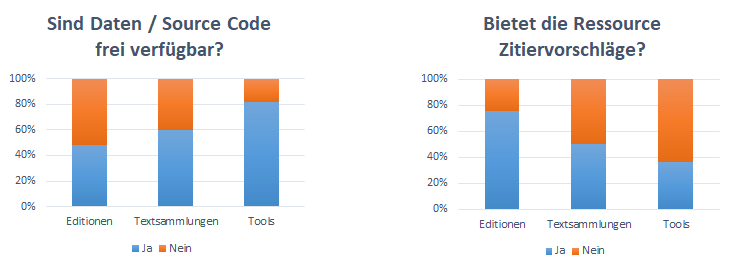
The factsheet data is also interesting beyond its role in the reviews, for example as a basis for determining differences and general trends (across all sectors) with regard to the objects of review.[10] For example, editions are at the bottom of the list of the three resource types in terms of the openness of the data or source code, while the reviewed text collections rely proportionately more frequently on open data and the reviewed tools even predominantly on open source code (Fig. 6). One possible explanation for this is that editions are primarily received ‚classically‘ via the graphical user interface, while text collections have more the character of a dataset. Edition tools, on the other hand, rarely function according to the plug-and-play principle, but usually have to be customised for specific projects, for which open source code is a prerequisite.
Fig. 6 / 7: Left: Are data / source code openly available? (Yes / No); Right: Does the resource offer citation guidelines? (Yes / No).
The picture is reversed when it comes to the citation of resource types (Fig. 7): In the reviewed editions, citation recommendations have largely prevailed, as the referencing of text is ultimately a core concern of editions. The tools bring up the rear here. There, citation standards or citation aids do not yet appear to have become established.
We have already reported and written in detail about RIDE’s goals and methods in other contexts,[11] so to mark the tenth anniversary, we would like to provide an insight into the work that happens behind the scenes on a daily basis and which is far too rarely visible. This includes, among other things: Finding authors, reviewing articles internally and providing helpful comments for revision, finding peer reviewers, formatting and converting reviews for publication, generating various publication formats (XML/TEI, HTML, PDF), ensuring the availability and archiving of articles (e.g. via DOI, APIs), promoting the journal issues. Long-term tasks include the maintenance and further development of the XML schema for the reviews and the further development of scripts and routines for processing the data for publication. The server on which RIDE’s WordPress instance runs also requires regular maintenance and the eXist-db instance, which we use for some functions, regularly needs to be upgraded to a newer version.
Fig. 8: The RIDE management team wins a poster award at DHd2022.
In addition to the editorial and technical tasks, we also take care of the scientific establishment and visibility of the journal. For example, RIDE recently received the open access seal of the Directory of Open Access Journals (DOAJ) and will soon be included in the Scopus database. Finally, the dissemination of our work in the national and international context is also an important part of our mission to keep the topic of „quality assurance of digital research resources“ present in the community. At the same time, we are raising the profile of RIDE and can attract new reviewers. Almost everything we do for RIDE is done on a voluntary basis and outside of our paid work, often in the evenings or at weekends. We are therefore particularly pleased when our work is recognised, such as third place for our entry in the DHd2022 poster competition (Fig. 8).
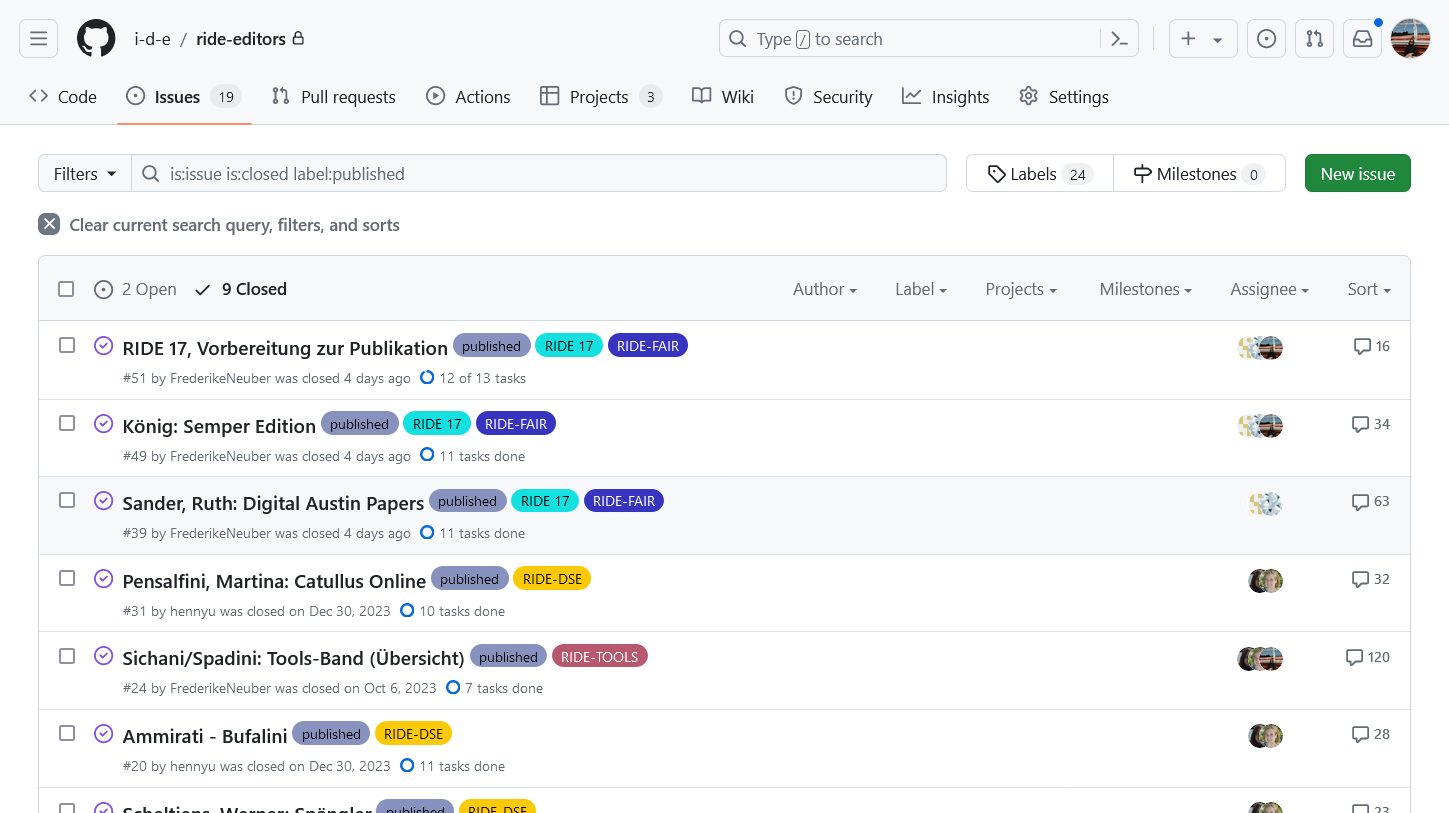
Abb. 9: The internal issue board of the RIDE editors.
We have been coordinating and organising all work for RIDE in internal GitHub repositories for some time now, using Issues, Project Board and Wiki (Fig. 9). As we want RIDE to be as open as possible, not only the review data, but also some scripts used in the publication process are available via public GitHub repositories and Zenodo.[12] Even though digital tools are needed to coordinate the publication of a journal these days, we actually prefer to discuss reviews and digital humanities in dimly lit pubs and make future plans for RIDE (Fig. 10 and 11).
Fig. 10: The RIDE launch in the legendary Celentano Bar in Cologne.
Fig. 11: Launch of the RIDE section „Text Collections“ in Elektra Bar, Cologne.
The continuous production of issues, the further development of the journal at various levels and the operation of the technical infrastructure require considerable (Wo|Man) power. RIDE is a joint project of the IDE and could not be realised without the many shoulders of its members. We also rely on the cooperation of the community: on the authors, who take the time to review digital resources in every detail and sometimes accept multiple revisions of their contributions; on the guest editors, who conscientiously continue our work with their own issues and at the same time provide new impulses; and on our Editorial Board, which provides spontaneous support for any problems. Last but not least, we can count on a network of peer reviewers, thanks to whom we can publish an ‚international peer-reviewed journal‘ according to the highest scientific quality standards and who provide valuable feedback on the reviews. We would like to take this opportunity to express our sincere thanks to all of them!
Finally, we would also like to thank our readers. We have received valuable feedback over the years, which has contributed to the development and improvement of RIDE. That’s why we’ve finally solved the pronunciation riddle: RIDE is of course Latin /ri:de/ from „ridere“ = „to laugh“. And with that, we say goodbye with a cheerful laugh, look forward to another 10 years of RIDE and finally switch back to English for the well-known and much-loved:
Enjoy the ride!
The members of the Institute for Documentology and Scholarly Editing
***
[1] See Philipp Steinkrüger, Ulrike Henny-Krahmer, Frederike Neuber and the members of the IDE, Editorial, March 2021, https://ride.i-d-e.de/about/editorial/. [2] See, for example, Frederike Neuber and Patrick Sahle, Nach den Büchern: Rezensionen digitaler Forschungsressourcen, H-Soz&Kult 2022, https://www.hsozkult.de/debate/id/fddebate-132457 for samples of reviews of digital research resources in historiographical review organs; Colleen Seidel, Digitale Forschung und Wissenschaftskommunikation – der Fall der mediävistischen Zeitschriften, DH@BUW 2022, https://dhbuw.hypotheses.org/319 for a more specialised study. It is also significant that even digital review platforms such as Sehepunkte almost exclusively provide a forum for printed contributions. [3] Patrick Sahle; in collaboration with Georg Vogeler and the members of the IDE; version 1.1, June 2014, http://www.i-d-e.de/publikationen/weitereschriften/kriterien-version-1-1/; Ulrike Henny-Krahmer and Frederike Neuber, in collaboration with the members of the IDE; version 1.0, February 2017, https://www.i-d-e.de/publikationen/weitereschriften/criteria-text-collections-version-1-0/; Anna-Maria Sichani and Elena Spadini, in collaboration with the members of the IDE; version 1.0, December 2018, https://www.i-d-e.de/publikationen/weitereschriften/criteria-tools-version-1/. [4]For example, with regard to the catalogue of criteria for reviewing text collections, José Calvo Tello, The Novel in the Spanish Silver Age (3. Data: Texts and Metadata), https://doi.org/10.14361/9783839459256-005, 3.1.2: „Its usefulness is beyond the specific frame of this journal, constituting a remarkable check-list for any new literary corpus.“ [5] 2014-19 Philipp Steinkrüger, 2019-22 Ulrike Henny-Krahmer and Frederike Neuber, from 2022 together with Martina Scholger. [6] On the initiative of Anna-Maria Sichani and Elena Spadini, the „Tools and Environments“ section was opened, the FAIR issues are published in cooperation with the NFDI consortium Text+ and with the participation of its staff (so far Tessa Gegnagel and Daniela Schulz). [7] RIDE offers various visualisations of the questionnaires for editions (https://ride.i-d-e.de/data/charts-scholarly-editions/) and text collections (https://ride.i-d-e.de/data/charts-text-collections/) to enable cross-review comparability of the resources. [8] The cross-review evaluation can be helpful in identifying such ‚agglomerations‘ and, if necessary, counteracting them by specifically trying to attract reviewers for resources from other disciplines and with other epochal foci. [9] The response options for the questionnaires on editions and text collections differ slightly and were mapped to each other. „Literary Studies / Philology“ in the editions questionnaire corresponds to „Literary Studies“ in the text collections, the category „Musicology“ only appears in the editions questionnaire, „Linguistics“ and „Archeology“ only in the text collections questionnaire. [10] See Claudia Resch, Digitale Editionen aus der Perspektive von Expert:innen und User:innen – Rezensionen der Zeitschrift RIDE im Meta-Review, in: Digitale Edition in Österreich / Digital Scholarly Edition in Austria, 2023, pp. 37-54 (urn:nbn:de:hbz:38-704476). [11] See, among others, Neuber / Sahle 2022 (note 2); Henny Ulrike, Reviewing digital editions in the context of evaluating digital research results, in: Digitale Metamorphose: Digital Humanities und Editionswissenschaft (ed. v. Roland S. Kamzelak and Timo Steyer), 2018. DOI: 10.17175/sb002_006;Markus Schnöpf, Evaluationskriterien für digitale Editionen und die reale Welt, in: HiN – Alexander Von Humboldt Im Netz 14(27), 69-76, DOI: 10.18443/182. [12] On the technical infrastructure of RIDE, see Henny-Krahmer, Ulrike; Frederike Neuber; Martina Scholger (2022): „Informationstechnologische Gedächtnisarbeit in der Rezensionszeitschrift RIDE“ [Poster]. In DHd 2022. cultures of digital memory. 8th Conference of the Association „Digital Humanities in German-speaking Countries“, Potsdam. Zenodo. DOI: 10.5281/zenodo.6322571
 Das IDE schaut in die Glaskugel und fragt: Wie werden sich digitale Editionen in den nächsten 20 Jahren entwickeln? Auf der Suche nach Antworten veranstalten wir am 02.-04. September 2026 in Wuppertal eine Konferenz und laden herzlich zu Paper-Proposals ein. Details dazu auf https://editopia2026.i-d-e.de/.
Das IDE schaut in die Glaskugel und fragt: Wie werden sich digitale Editionen in den nächsten 20 Jahren entwickeln? Auf der Suche nach Antworten veranstalten wir am 02.-04. September 2026 in Wuppertal eine Konferenz und laden herzlich zu Paper-Proposals ein. Details dazu auf https://editopia2026.i-d-e.de/.